NCP-AII Training For Exam, NCP-AII Exam Dump
Wiki Article
DOWNLOAD the newest PassExamDumps NCP-AII PDF dumps from Cloud Storage for free: https://drive.google.com/open?id=1wL2b7AFgdP9EtJnlLTTZ1ahR7NFXAzsJ
If you study with our NCP-AII exam questions, you will have a 99% chance to pass the exam. Of course, you don't have to buy any other study materials. Our NCP-AII exam questions can satisfy all your learning needs. During this time, you must really be learning. If you just put NCP-AII Real Exam in front of them and didn't look at them, then we have no way. Our NCP-AII exam questions want to work with you to help you achieve your dreams.
NVIDIA NCP-AII Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
>> NCP-AII Training For Exam <<
Newest 100% Free NCP-AII – 100% Free Training For Exam | NCP-AII Exam Dump
Though the quality of our NCP-AII exam questions are the best in the career as we have engaged for over ten years and we are always working on the NCP-AII practice guide to make it better. But if you visit our website, you will find that our prices of the NCP-AII training prep are not high at all. Every candidate can afford it, even the students in the universities can buy it without any pressure. And we will give discounts on the NCP-AII learning materials from time to time.
NVIDIA AI Infrastructure Sample Questions (Q118-Q123):
NEW QUESTION # 118
A system engineer needs to set the vGPU scheduling behavior for all GPUs to share the scheduling equally with the default time slice length. What command should be used?
- A. esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords=RmPVMRL=0x01"
- B. esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords=RmPVMRL=0x00"
- C. esxcli graphics module parameters set -m nvidia -p "NVreg_RegistryDwords=RmPVMRL=0x01"
- D. esxcli system module parameters set -m nvidia -p "NVreg_RegistryDwords=FRL=0x01"
Answer: A
Explanation:
When deploying NVIDIA vGPU on VMware ESXi, the NVIDIA driver provides several scheduling policies to determine how GPU physical resources are shared among multiple virtual machines. The default behavior is often the "Best Effort" scheduler, but for environments requiring predictable performance across all users, the "Equal Share" scheduler is preferred. This scheduler gives each vGPU an equal "time slice" of the physical GPU's engines. The configuration is managed via module parameters passed to the nvidia kernel driver during host boot. The specific registry key for this behavior is RmPVMRL. Setting RmPVMRL=0x01 enables the Equal Share scheduler (Option A). Conversely, 0x00 would revert to the default time-sliced behavior. It is critical to use system module parameters set to ensure the setting persists across reboots and is applied globally to the NVIDIA driver stack. This ensures that no single "noisy neighbor" VM can monopolize the GPU cycles, which is a common requirement in shared AI research labs or virtual desktop infrastructures where consistency is more important than raw peak throughput of a single task.
NEW QUESTION # 119
A system administrator receives an alert about a potential hardware fault on an NVIDIA DGX A100. The GPU performance seems degraded, and the system fans are operating loudly. What step should be recommended to identify and troubleshoot the hardware fault?
- A. Run a deep learning workload to stress test the GPUs and check whether the issue persists.
- B. Increase the fan speed to maximum and check whether the performance improves.
- C. Power drain then restart the DGX and check if the performance degradation resolves.
- D. Check the NVIDIA System Management Interface (nvidia-smi) for GPU status and temperatures.
Answer: D
Explanation:
When a DGX system exhibits high fan speeds and performance degradation, it is typically engaging in Thermal Throttling. High-performance GPUs like the A100 or H100 will automatically reduce their clock speeds (and thus performance) if they exceed safe temperature thresholds. The first and most critical diagnostic step is to run nvidia-smi. This utility provides immediate, real-time telemetry on GPU temperatures, power draw, and " Clocks Throttle Reasons. " By reviewing the output, an administrator can see if " Thermal " is listed as the reason for reduced clocks. This identifies whether the issue is environmental (blocked airflow/hot aisle temperature) or hardware-specific (a failed GPU thermal interface or a dead internal fan). Running more workloads (Option A) would exacerbate the heat, while a power drain (Option C) is a " last resort " that doesn ' t provide diagnostic data. nvidia-smi provides the evidentiary data needed to determine if an RMA (Return Merchandise Authorization) is required for the GPU tray.
NEW QUESTION # 120
An infrastructure engineer in an AI factory has successfully replaced a power supply unit on an NVIDIA DGX H100. After installation, both the IN and OUT LEDs on the new power supply illuminate solid green.
Which NVSM CLI command should the engineer use to quickly verify the overall system status and ensure it is operating as expected?
- A. nvsm show power
- B. nvsm show alerts
- C. nvsm show health
- D. nvsm show powermode
Answer: C
Explanation:
The NVIDIA System Management (NVSM) tool is the definitive CLI utility for monitoring the health of DGX platforms. While replacing a PSU (Power Supply Unit) is a common maintenance task, verifying that the new component is correctly integrated into the system's health model is mandatory. While nvsm show power would provide specific data regarding wattage and voltage for the PSU, the most comprehensive way to ensure the replacement hasn ' t caused secondary issues or that the system hasn ' t remained in a " Degraded
" state is to run nvsm show health. This command performs a global check across all subsystems: GPUs, NVLink switches, storage, fans, and power. If the PSU replacement was successful and the system is back to full redundancy, nvsm show health will return a " Healthy " status. In an AI factory setting, where DGX H100 nodes pull significant power, ensuring that all 6 PSUs (in an N+N or N+1 configuration) are not only physically green but logically acknowledged by the Baseboard Management Controller (BMC) is critical for preventing unexpected shutdowns during high-load training iterations.
NEW QUESTION # 121
Consider the following Dockerfile snippet: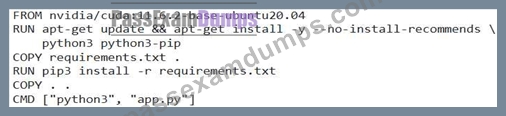
This Dockerfile is used to build a deep learning application. After building and running a container from this image, you observe that the application is not detecting the GPU. You have verified that the NVIDIA Container Toolkit is installed and configured correctly on the host. What is the most likely reason for this issue?
- A. The 'docker run' command is missing the '-gpus all' flag.
- B. The 'requirements.txt' file is missing the 'nvidia-pyindex' package.
- C. The CUDA version on the host is different than the one specified in the Dockerfile.
- D. The base image 'nvidia/cuda:ll .6.2-base-ubuntu20.04' does not include the necessary NVIDIA Container Toolkit components.
- E. The application code in 'app.py' is not explicitly requesting GPU resources.
Answer: A
Explanation:
The 'docker run' command must include the =gpus all' (or equivalent) flag to explicitly request GPU resources for the container (C). The base image 'nvidia/cuda:ll .6.2-base-ubuntu20.04' provides the CUDA runtime, but the NVIDIA Container Toolkit on the host handles the GPU device mapping. The application code (B) doesn't need to explicitly request GPUs; the CUDA runtime will handle that. 'nvidia-pyindex' (D) is related to package management, not GPU detection. The Dockerfile includes a specific CUDA version that mitigates version differences (E). The base image does not include the Container Toolkit, which is installed on the HOST.
NEW QUESTION # 122
A cluster administrator needs to validate transceiver firmware versions across 200 ports using UFM. Which GUI-based method provides a consolidated view?
- A. Run mlxlink -d lid-<LID> -m on each port manually.
- B. Export all switch logs and grep for 'FW Version".
- C. Navigate to 'Devices" > select a switch > "Cables' tab to see ASIC firmware and transceiver versions.
- D. Use "Topology' view to visually inspect cable icons.
Answer: C
Explanation:
Managing a large-scale AI fabric requires centralized visibility into the physical layer. The NVIDIAUnified Fabric Manager (UFM)provides a comprehensive Dashboard for InfiniBand networks. To check transceiver firmware-which is critical for ensuring feature parity and stability across the fabric-the administrator can use the UFM Enterprise GUI. By navigating to the "Devices" section and selecting a specific switch, the
"Cables" tab will aggregate telemetry for every occupied port. This view displays the manufacturer, part number, and the specific firmware version of the transceivers (LinkX) or Active Optical Cables (AOC). This consolidated view is far more efficient than manual CLI queries (Option C) for 200+ ports. Maintaining uniform firmware across transceivers ensures that optimizations like Adaptive Routing and Congestion Control perform consistently across the entire 400G or 200G fabric.
NEW QUESTION # 123
......
Our NVIDIA AI Infrastructure (NCP-AII) exam dumps are useful for preparation and a complete source of knowledge. If you are a full-time job holder and facing problems finding time to prepare for the NVIDIA AI Infrastructure (NCP-AII) exam questions, you shouldn't worry more about it. One of the main unique qualities of the PassExamDumps NVIDIA Exam Questions is its ease of use. Our practice exam simulators are user and beginner friendly. You can use NVIDIA AI Infrastructure (NCP-AII) PDF dumps and Web-based software without installation. NVIDIA AI Infrastructure (NCP-AII) PDF questions work on all the devices like smartphones, Macs, tablets, Windows, etc. We know that it is hard to stay and study for the NVIDIA AI Infrastructure (NCP-AII) exam dumps in one place for a long time. Therefore, you have the option to use NVIDIA AI Infrastructure (NCP-AII) PDF questions anywhere and anytime.
NCP-AII Exam Dump: https://www.passexamdumps.com/NCP-AII-valid-exam-dumps.html
- Real NVIDIA AI Infrastructure Pass4sure Torrent - NCP-AII Study Pdf - NVIDIA AI Infrastructure Practice Questions ???? Easily obtain ➥ NCP-AII ???? for free download through 「 www.troytecdumps.com 」 ????NCP-AII Exam Dumps
- Dumps NCP-AII Guide ???? NCP-AII Exam Dumps ???? NCP-AII Reliable Test Syllabus ???? Open ▛ www.pdfvce.com ▟ enter 【 NCP-AII 】 and obtain a free download ????Valid NCP-AII Test Prep
- New NCP-AII Braindumps Pdf ???? NCP-AII Detail Explanation ???? Exam NCP-AII Collection ???? Enter ➥ www.easy4engine.com ???? and search for ➽ NCP-AII ???? to download for free ????NCP-AII Exam Dumps
- Pass-Sure NCP-AII Training For Exam | NCP-AII 100% Free Exam Dump ✏ Easily obtain free download of ☀ NCP-AII ️☀️ by searching on ( www.pdfvce.com ) ????NCP-AII Latest Exam Papers
- Pass Guaranteed NVIDIA - High Pass-Rate NCP-AII - NVIDIA AI Infrastructure Training For Exam ???? Download ⮆ NCP-AII ⮄ for free by simply searching on [ www.pass4test.com ] ☘Valid Exam NCP-AII Book
- Three Easy-to-Use Pdfvce NVIDIA NCP-AII Exam Practice Questions Formats ???? Download ☀ NCP-AII ️☀️ for free by simply entering ⮆ www.pdfvce.com ⮄ website ????NCP-AII Valid Exam Review
- NCP-AII Latest Exam Papers ???? Valid NCP-AII Test Prep ⛽ NCP-AII Exam Dumps ???? Download ⮆ NCP-AII ⮄ for free by simply searching on ➥ www.validtorrent.com ???? ????Exam NCP-AII Collection
- Test NCP-AII Simulator Free ???? Test NCP-AII Simulator Free ???? NCP-AII Latest Exam Papers ???? Open website ➠ www.pdfvce.com ???? and search for ⮆ NCP-AII ⮄ for free download ????NCP-AII Upgrade Dumps
- Pass-Sure NCP-AII Training For Exam | NCP-AII 100% Free Exam Dump ???? Search for ⏩ NCP-AII ⏪ and easily obtain a free download on ( www.verifieddumps.com ) ????Valid Exam NCP-AII Book
- 2026 NCP-AII Training For Exam: NVIDIA AI Infrastructure - High-quality NVIDIA NCP-AII Exam Dump ???? The page for free download of ( NCP-AII ) on ⮆ www.pdfvce.com ⮄ will open immediately ????Valid NCP-AII Test Prep
- NCP-AII - NVIDIA AI Infrastructure Marvelous Training For Exam ???? Simply search for ➥ NCP-AII ???? for free download on ➥ www.vceengine.com ???? ????Valid NCP-AII Exam Sims
- hannajvdq413746.wikicarrier.com, yxzbookmarks.com, hassanjviw683472.glifeblog.com, bookmarkinglog.com, bookmarkbirth.com, myavnkz368574.eveowiki.com, finnianmwgc212031.blogspothub.com, bookmarkingquest.com, hamzatqbm498790.life-wiki.com, barbaraegkc761307.wikinewspaper.com, Disposable vapes
P.S. Free 2026 NVIDIA NCP-AII dumps are available on Google Drive shared by PassExamDumps: https://drive.google.com/open?id=1wL2b7AFgdP9EtJnlLTTZ1ahR7NFXAzsJ
Report this wiki page